You’re never too old for (deep) learning
The artificial grandma brain
Our brain converts signals that we receive from the outside world through our eyes or ears into information such as images and sounds. Artificial neural networks typically claim they mimic the behaviour of the neurons in our brains. As far as marketing is concerned, the analogy is welcome, scientifically however, the similarities are rather limited. While indeed neural networks were (originally) inspired to impersonate grandma’s brain, the focus shifted quickly towards practical applications, with fewer sidetracks attempting to recreate biological similarity.
In deep learning, we take the biological analogy one step further. We know that our brain typically processes signals in a hierarchical fashion with certain area’s preprocessing and distilling information to be passed on to other specialized neuron groups. This is the key analogy with deep learning algorithms, which are intelligently designed hierarchical layers of artificial neurons.
Where our brain is fed signals from the outside world, an artificial neural network is fed data such as images, sounds, time series or text. Using the pixels of a photo as an example, a neural network scans and analyzes different groups of pixels. As the data passes deeper through the neural net, higher-level features are automatically discerned. In the first layers, it analyzes local patterns such as contours of objects or the curvature of lines. In deeper layers, these patterns are combined to form shapes such as eyes or ears. With each layer, the understanding of the picture becomes increasingly high level. This goes all the way to where the neural net is confident to make its final decision.
Is it an airplane, a bird or is it that Mega Mindy girl which our granddaughter always wants to watch on television?
Layer after layer after layer after layer
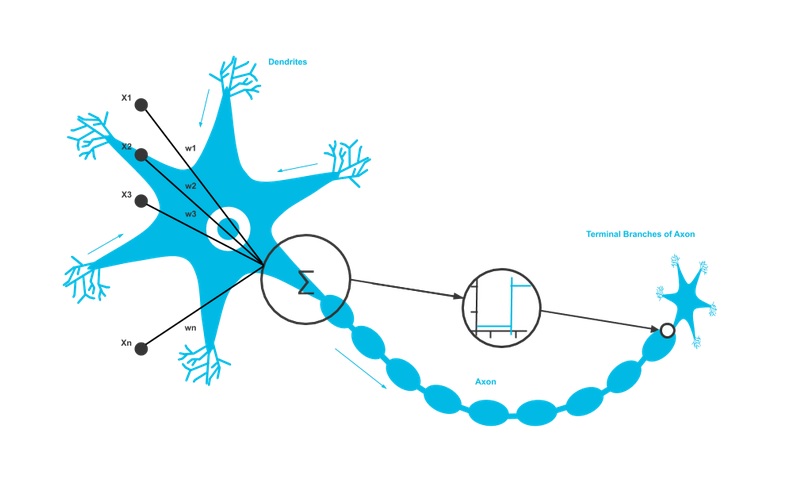
The first layer of an artificial neural network is called the input layer and is directly connected to the so-called hidden layers that perform calculations on the input. Deep learning refers to the sizable depth of the neural network i.e. the number of layers. The hidden layers of the network are where the magic happens.
Nodes in the network are activated when they receive sufficient stimuli. These nodes take multiple inputs and calculate an output. Output from one node can be an input for another node. The nodes are connected to each other by edges that have a certain weight that reinforces or tempers the input, assigning meaning to the input in relation to the task the algorithm is trying to solve. These weights are multiplied with the input value, are summed and then the sum is passed through the activation function of a node to determine to what extent that the signal should be passed further through the network to influence the final outcome.
Linking the adjustable weights of the model to input features is how meaning can be assigned to those features with regard to how the neural network classifies the input. In the final layer, a probability percentage can be returned for every class, i.e. 2% bird, 94% airplane and 4% Mega Mindy. This way, we can understand how certain the neural network is about its decision.
Going deeper in the network
There is no strict rule of when a network classifies as a deep learning network. The more layers we introduce, the more flexibility the network gains and typically how much the decision process can be divided into a constructive process. As the number of layers of trainable neurons increases, so does the amount of data and computational power we need.
Each node in a layer trains on a different set of features consisting of the outputs of the previous layer. Deeper in the neural network more complex features can be recognized. This is because they aggregate and recombine features from the previous layer. This is known as a feature hierarchy with increasing complexity and abstraction. This hierarchical approach makes deep neural networks suitable for processing data sets with complex correlations such as spatial and temporal connections.
So what makes deep learning special?
Unlike many traditional machine-learning algorithms, deep networks perform automatic feature learning as opposed to manual feature engineering. Since feature extraction is often a time-consuming task and not straightforward, deep learning provides a way to bypass this in problems where we struggle to reason about optimal features.
In general, introducing manual intervention in the learning process typically results in sub-optimal performance. Deep learning removes the classical feature engineering part from the machine learning pipeline, at the cost of increased data needs.
Machine Learning and Deep Learning
Deep learning is an amazing technology that is key to many technological evolutions in the past decade. Despite economic disadvantages such as the requirement of expensive computing material (GPU, TPU clusters) and often time-consuming labelling efforts, deep learning has proven that the seemingly magical result is worth the price.
However, we must be careful that the popularity of deep learning does not harm the general value offering that machine learning provides. Machine learning introduces a new way of thinking in which solutions are automatically constructed based on historical data, as opposed to human intelligence that is mapped into rules and software. Deep learning is just a tool in the toolbox and grandma knows it takes more than a hammer to build a house.
Want to know more? Contact us! We’d love to answer any questions you may have.