A crash course into Natural Language Processing
In our first three-part series, we will begin with an introduction to NLP. What does it mean, and how does it work?
Text is the largest human-generated data source on the planet, and it still grows exponentially daily. The text we type on our keyboards or mobile devices is an essential means we humans like to communicate our thoughts and document our stories. Critical text property is typically unstructured data, and precisely this ‘free-form’ expression causes machines to have a virtual headache.
As a result, many companies don’t tap into the potential of their unstructured text data, whether internal reports, customer interactions, service logs or case files. Indeed, such data is typically harder to process, automate and interpret for computer systems. However, let us convince you that this shouldn’t excuse decision-makers from missing opportunities to turn this data into meaningful information and impactful actions.
Let’s begin.

What is natural language processing? (NLP)
NLP stands for Natural Language Processing and has grown into a fully-fledged branch of AI. In a nutshell, NLP makes it possible for computers to understand human language while still retaining the ability to process data much faster than humans.
While natural language processing isn’t a new science, the technology is rapidly advancing thanks to an increased interest in human-to-machine communications, plus an availability of big data, powerful computing and enhanced algorithms.
Why is NLP important?
Processing large volumes of textual data
Today’s machines can analyse more language-based data than humans without needing a break and in a consistent (and if constructed well) unbiased way. Automation will be critical to thoroughly analysing text and speech data, considering the staggering amount of unstructured data generated daily, from medical records to social media.
The most well-known examples are Google Assistant, Siri and Alexa. People use Google translate every day to translate text into all kinds of different languages. Or the app Grammarly helps people improve their writing skills by automatically detecting grammar and spelling mistakes.
Another well-known application of NLP is chatbots, where you can have a more natural conversation with a computer to solve issues. Your spam filter also uses NLP technology to keep unwanted promotional emails out of your inbox.
Of course, they are still far from perfect, but the increase in accuracy has made giant leaps in the past decade.
Imagine the revelations of all the massive amounts of unstructured text you gather in your organisation and from your stakeholders. It may hold the key to the best strategy for your organisation ever.

Structuring a highly unstructured data source
We might not always be aware of it, but we, colleagues on the work floor, do not always communicate clearly. The way we chat since the dawn of the internet hasn’t made it all that more accessible, reading through all the colloquialisms, abbreviations and misspellings. As frustratingly it is for us to keep track of all these different communication styles and information sources, imagine how it would be for a software program.
But with the help of NLP, computer programs made considerable leaps to analyse and interpret human language and position them in an appropriate context.
A revolutionary approach
First, to automate these processes and deliver accurate responses, you’ll need machine learning—the ability to instruct computer programs to learn from data automatically.
This is where the expertise of ML2Grow comes into play.
To recap, machine learning is the process of applying algorithms that teach machines how to learn and improve from experience without being explicitly programmed automatically.
The first step is to know what the machine needs to learn. We create a learning framework and provide relevant and clean data for the device to learn from. Input is vital here—garbage in, garbage out.
AI-powered chatbots, for example, use NLP to interpret what users say and what they intend to do and machine learning to automatically deliver more accurate responses by learning from hundreds or thousands of past interactions.
Unlike a programmed tool you can buy everywhere, a machine learning model can generalise and deal with novel cases. If the model stumbles on something it has seen before, it can use its prior learning to evaluate the circumstance.
The excellent value for businesses is that NLP features can turn unstructured text into useable data and insights in no time and where the model continuously improves at the task you’ve set.
We can put any text into our machine model: social media comments, online reviews, survey responses, and even financial, medical, legal and regulatory documents.
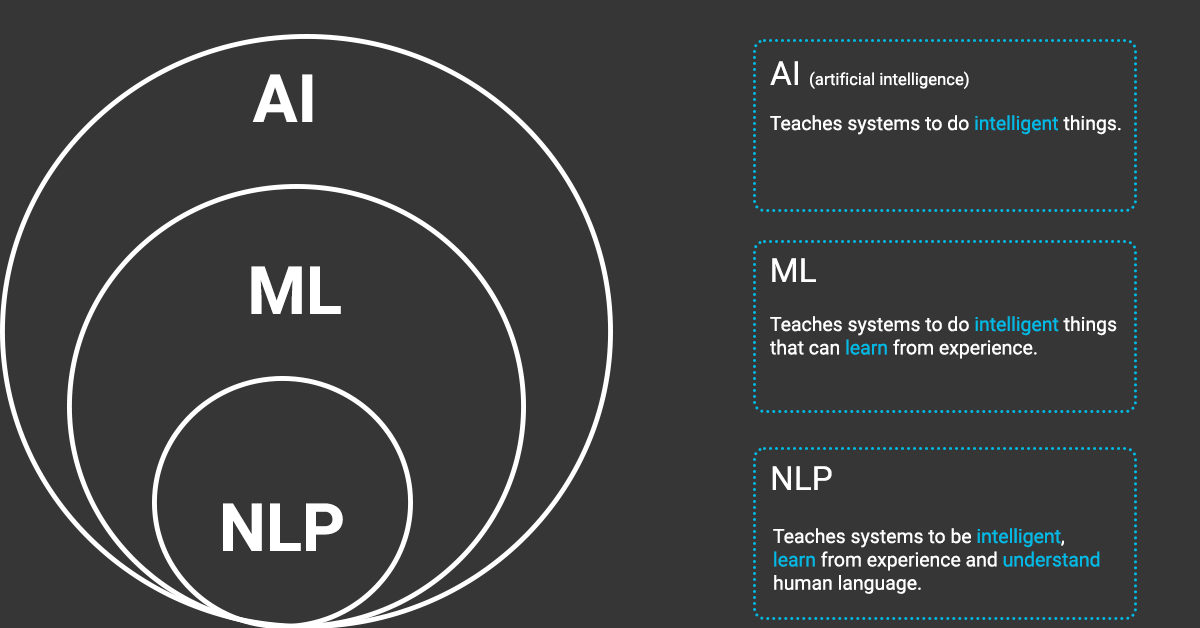
How does it work?
In general terms, NLP tasks break down language into shorter, elemental pieces, try to understand relationships between the parts and explore how the details work together to create meaning.
When you look at a chunk of text, there are always three crucial layers to analyse.
Semantic information
Semantic information is the specific meaning of an individual word. For example, ‘crash’ can mean an auto accident, a drop in the stock market, attending a party without being invited or ocean waves hitting the shore.
Sentences and words can have many different interpretations, e.g. consider the sentence: “Greg’s ball cleared the fence.” Europeans think ‘the ball’ refers to a soccer ball, while most Americans think of a baseball instead. Without NLP systems, a computer can’t process the context.
Syntax information
The second key text component is a sentence or phrase structure, known as syntax information. In NLP, the syntactic analysis assesses how the natural language aligns with the grammatical rules.
Take, for example, the sentence: “Although they were tired after the marathon, the cousins decided to go to a celebration at the park.” Who are ‘they’, the cousins or someone else?
Context information
And at last, we must understand the context of a word or sentence. What is the concept being discussed? “It was an idyllic day to walk in the park.” What is the meaning of ‘idyllic’, and why was it perfect for walking in the park? Probably because it was warm and sunny.
The analyses are vital to understanding the grammatical structure of a text and identifying how words relate to each other in a given context. But, transforming text into something machines can process is complicated.

A brief overview of NLP tasks
Basic NLP preprocessing and learning tasks include tokenisation and parsing, lemmatisation/stemming, part-of-speech tagging, language detection, and identifying semantic relationships. You’ve done these tasks manually if you ever diagrammed sentences in grade school.
Several techniques can be used to ‘clean’ a dataset and make it more organised.
Part-of-speech tagging
It is the process of determining the part-of-speech (POS) of a particular word or piece of text based on its use and context. It describes the characteristic structure of lexical terms within a sentence or text. Therefore, we can use them to make assumptions about semantics. Other applications of POS tagging include:
Named entity recognition
Identifies words or phrases as valuable entities. For example, NEM identifies ‘Ghent’ as a location and ‘Greg’ as a man’s name.
Co-reference resolution
It is the task of identifying if and when two words refer to the same entity. For example, ‘he’ = ‘Greg’.
Speech recognition
It is the task of reliably converting voice data into text data. Speech recognition is required for any application that follows voice commands or answers spoken questions.
Word sense disambiguation
It is the selection of the meaning of a word with multiple meanings through a process of semantic analysis that determines the word that makes the most sense in the given context.
Tokenisation
When a document is split into sentences, it’s easier to process them one at a time. The next step is to separate the sentence into separate words or tokens. This is why it’s called tokenisation. It would look something like this:

Stop word removal
The next step could be the removal of common words that add little or no unique information, such as prepositions and articles (“over”, “the”).
Stemming
Refers to the process of slicing the end of the beginning of words to remove affixes and suffixes. The problem is that affixes can create or expand new forms of the same comment. “Greg helps bring the ball back to the playing ground”. Take, for example, “helpful”, and “full” is the suffix here attached at the end of the word.
We make the computer chop the part to the word “help”. We use this to correct spelling errors from tokens. This is not used as a grammar exercise for the computer but to improve the performance of our NLP model.

Lemmatisation
Unlike stemming, lemmatisation depends on correctly identifying the intended part of speech and the meaning of a word in a sentence.
For example, the words “shooting”, “shoots”, and” shot” are all part of the same verb. “Greg is shooting the ball” or “Greg shot the ball” means the same for us but in a different conjugation. For a computer, it is helpful to know the base form of each word so that you know that both sentences are talking about the same concept. So the base form of the verb is “shoot”.
Lemmatisation is figuring out the most basic form or lemma of each word in the sentence. In our example, it’s finding the root form of our verb “shooting”.
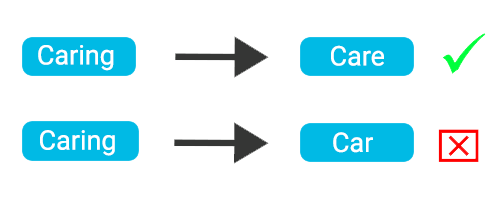
Example of lemmatisation (care) vs stemming (car).
NLP libraries
Natural language processing is one of the most complex fields within artificial intelligence. But manually doing the above would be sheer impossible. Many NLP libraries are doing all that hard work so that our machine learning engineers can focus on making the models work perfectly rather than wasting time on sentiment analysis or keyword extraction.
Next time we will discuss some of the most popular open-source NLP libraries our team uses and why a custom-made solution can be an alternative to off-the-shelve solutions.


