Finding your face in a Machine Learning model
If you want to get straight in the action you can run the colab yourself.
If you want to know how it works read on. Next week we will have a closer look at the generator and do some cool image transformations.
Generative Adversarial Network
Stylegan is GAN-based model which stands for Generative Adversarial Network. There are 2 main branches in machine learning relevant to the stylegan model.
Supervised learning
We provide the model with data and linked to that data are labels ( the solutions). These models train by example. Applications might be object recognition, prediction energy usage, image classification,…
Unsupervised learning
We provide the model with data but no labels. These types of models learn to find structure in the data. These models do not predict but they learn to structurize and generalize out of the data or even create new data. Examples: customer segmentation, visualizing complex data, encoding data.
StyleGan is an unsupervised model, It takes a dataset of images and generates new images which are similar to the original dataset. In this case, faces. That’s the Generative part.
The data used to train this model consists of a large set of images of portraits (70,000) compiled by the team at Nvidia and made open source.

It is adversarial because this model actually consists of 2 smaller networks. Each with his/her own goal: trying to mess with its counterpart!
A dramatized version of how the model works
In the left corner you have The Generator aka the Artist:
The artist just wants to draw things, he is the source of endless images. In this case, he really wants to draw faces. But there is a catch, he actually never saw a picture of a real person in his life. Typical, how arrogant!

In the right corner we have The Classifier aka the Critic
The critic doesn’t know a thing about drawing her own images but all she wants to do is put that arrogant artist in his place. Let’s just say she wants things to be clean and tidy and thinks she can recognize a fake from a Picasso by smelling it!

Let the battle begin!
This isn’t a physical contact sport, they are separated by a virtually impenetrable wall. No, this is a game about deceit. The rules are simple.
First step:
The generator/artist draws an image.
Second step:
A random image from the original datasets is taken,(a real picture of a person)
Third step:
The classifier/critic gets both these images but does not know which. It has to guess!
Final step: the reckoning
There are 2 possible outcomes.
The classifier/critic was right:
Good for her, she gets a cookie and they tell her:
“Whatever you did to decide was good, do it some more!”
The poor artist, on the other hand, gets a slap on the head: “Is this what we put you through art college for?!? You are awful whatever you did, draw the opposite the next time! ”
The classifier/critic was wrong:
Now the generator/artist gets all the glory: “You are an amazing master painter genius, we want even more of what you just did.”
The critic, on the other hand, gets a knock on the head:” Do you even know the difference between an African and European swallow? Whatever you used to try and recognize the fake from the real one was wrong”
Go back to step 1 and repeat a zillion times!
Which face is real?
You might think this is a roundabout way of designing a computer program to learn to draw, even a bit sadistic. But this is the way of the deep neural network! By not giving the original images to the generator the model has a harder time overfitting. Overfitting, in this case, would be that instead of the model learning to draw faces it learns the images by heart and can only copy the images of the original dataset. So by separating the model into 2 parts, we hope that model learns to generalize what you need to draw a face.
Although they are adversaries they both get opportunities to learn if their rival gets better. The generator never sees an actual image, it learns only if the critic caught his fake. If the critic gets better he gets more opportunities to learn what works and what doesn’t. If the generator improves the critic gets a harder job separating the fakes from the original so it gets a chance to learn something new.
(Also no algorithms actually get hurt or knocked on the head, I am just taking some artistic liberty with describing matrix multiplication backpropagation and gradient descent.)
At the start, it just creates nonsense, just weird noise bursts because neither network knows what it is doing but let these two play their games for a few billion years and at last we have a generator that can draw photorealistic faces! Thank goodness we have modern computers and GPU farms that can train this model in a few weeks. And that’s what they did at Nvidia and the results are pretty amazing, these people don’t actually exist:
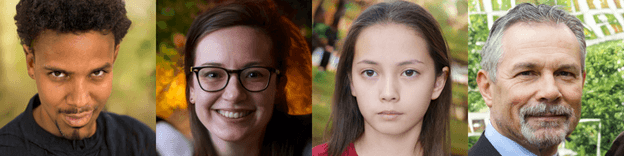
There is a site where you can play the role of the critic and try to find out which person is real: https://www.whichfaceisreal.com/index.php (small tip: real people seem to have more detailed backgrounds, something model still struggles with which is logical there is a lot more variation in backgrounds)
Have fun!
