Information extraction & summarisation with NLP
Information extraction
Information extraction helps you process large amounts of unstructured data and organise it into structured information. E.g. it enables you to recognise and extract relevant features (such as product codes, colours and specifications) or named entities (such as the names of people, locations, or company’s terms).
Companies have always collected large amounts of data for their internal operations or due to regulatory reasons. However, a significant portion of these documents is recorded as unstructured free text, which is often never looked at again and is impracticable to process. In addition, this data might be siloed for different business functions inside a company, and practical information search and discovery is challenging in its traditional form.

Information extraction then & now
How does information extraction work
There are many subtleties and complex techniques involved in the process of information extraction, but a good start for a beginner is to remember:
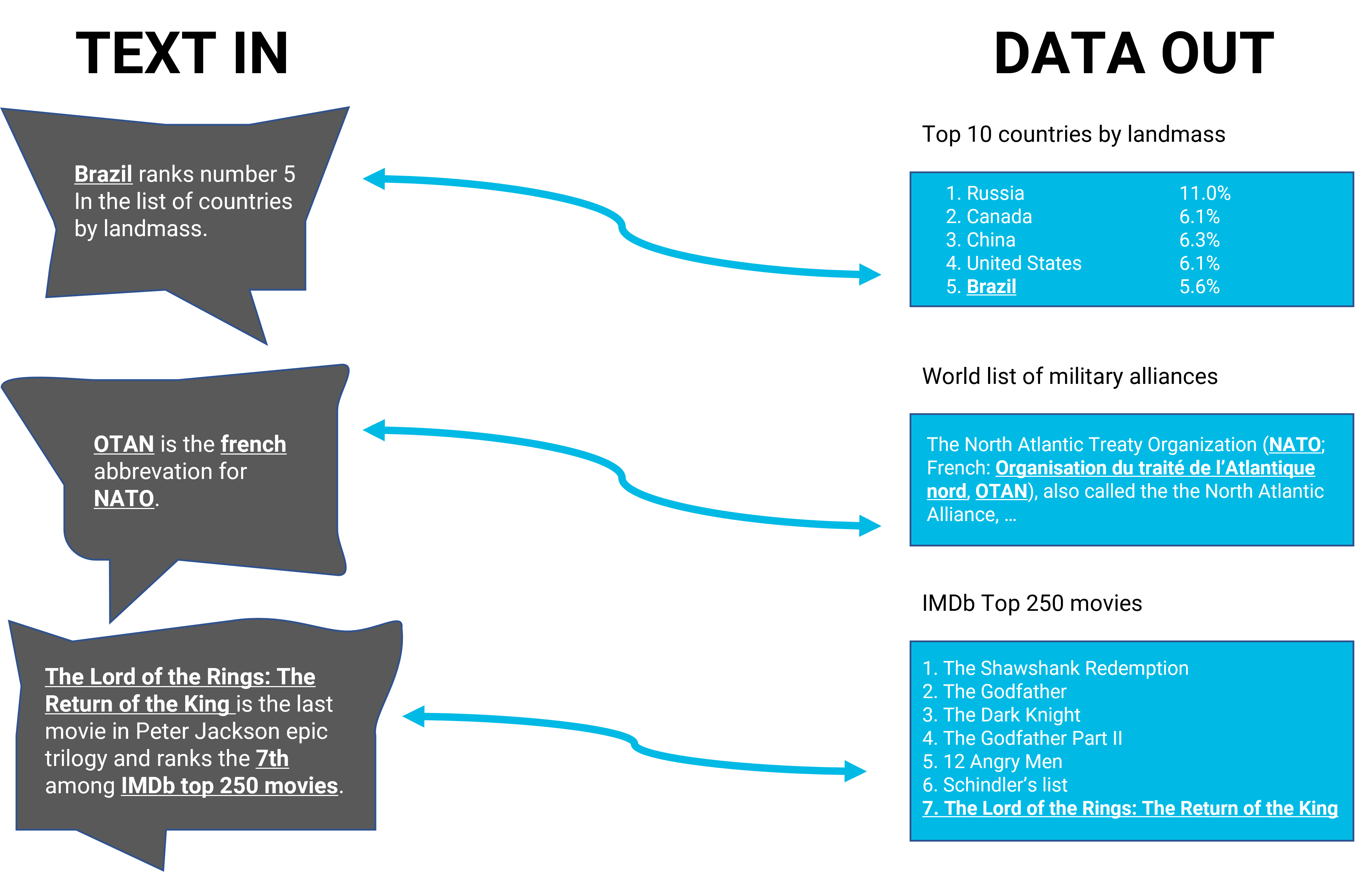
To elaborate a bit on this minimalist way of describing information extraction, the process involves transforming an unstructured text or a collection of texts into sets of facts (i.e., formal, machine-readable statements of the type “Peter Jackson is the director of Lord of the Rings: The Return of the King “) that are further populated (filled) in a database.
Typically, for structured information to be extracted from unstructured texts, the following main subtasks are involved:
- Pre-processing of the text – this is where the text is prepared for processing with the help of computational linguistics tools such as tokenisation, sentence splitting, morphological analysis, etc.
- Finding and classifying concepts is where mentions of people, things, locations, events and other pre-specified concepts are detected and classified.
- Connecting the concepts involves identifying relationships between the extracted concepts.
- Unifying – this subtask presents the extracted data in a standard form.
- Getting rid of the noise – this subtask involves eliminating duplicate data.
- Enriching your knowledge base is where the extracted knowledge is ingested into your database for further use.
Information extraction can be entirely automated or performed with the help of human input.
Typically, the best information extraction solutions combine automated methods and human processing.
Example:
Through information extraction, the following basic facts can be pulled out of a free-flowing text and organised in a structured, machine-readable form.
Let’s take this article from the Washington Post.

It’s a relatively long article containing more than 1800 words. Now imagine you need to extract the keywords from this article very fast.
You want to know where this is happening, what armies are fighting there, and what organisations and persons are mentioned in this article.
In our previous blogpost’ 4 NLP libraries that are awesome’, we talked a little bit about NLP libraries that can solve NLP problems quick. In addition, many pre-trained transformer models can be used. E.g. BERT or (BERT-variants)
BERT is a transformer-based machine learning technique for NLP, originally developed by Google. It can be tuned for different purposes. The one we will use is a fine-tuned version that is ready to use for NER or Named Entity Recognition. It will be the perfect tool to recognise the four types of entities that we want to know: location (LOC), organisations (ORG) and person (PER).
How to use
You can use this model with transformers pipeline for NER
from transformers import AutoTokenizer, AutoModelForTokenClassification
from transformers import pipeline
tokenizer = AutoTokenizer.from_pretrained("dslim/bert-base-NER")
model = AutoModelForTokenClassification.from_pretrained("dslim/bert-base-NER")
nlp = pipeline("ner", model=model, tokenizer=tokenizer)
example = “Ukrainian troops on Tuesday accelerated their military advances on two fronts, pushing Russian forces into retreat in the Donetsk and Luhansk regions to the east and Kherson region to the south.”
ner_results = nlp(example)
print(ner_results)
Output
When we compute the article, we get this result:

Summarisation
Machines can consistently and rapidly analyse more language-based data than humans and do not need to stop for a break.
Summarisation allows you to:
- Identify the most relevant information and shorten texts
- Turn unstructured text into useable data
- Process all kinds of texts, including social media comments, online reviews and even financial, medical and legal documents
Typically two kinds of summarisation are distinguised: extractive and abstractive. The first abbreviates texts by returning extracted key sentences, the latter generates a (completely) new text based on the content.
Example
For summarisation, we don’t use BERT but his brother BART.
BART is a transformer encoder-encoder (seq2seq) model with a bidirectional (BERT-like) encoder and an autoregressive (GPT-like) decoder. BART is pre-trained by corrupting text with an arbitrary noising function and learning a model to reconstruct the original text.
BART is particularly effective when fine-tuned for text generation (e.g. summarisation, translation) but also works well for comprehension tasks (e.g. text classification, question answering). This particular checkpoint has been fine-tuned on CNN Daily Mail, an extensive collection of text-summary pairs.
How to use
from transformers import pipeline
summarizer = pipeline("summarization", model="facebook/bart-large-cnn")
ARTICLE = “Ukrainian troops on Tuesday accelerated their military advances on two fronts, pushing Russian forces into retreat in the Donetsk and Luhansk regions to the east and Kherson region to the south...”
print(summarizer(ARTICLE, max_length=130, min_length=30, do_sample=False))
[{‘summary_text’: ‘Ukrainian forces pushed ahead dozens of miles into the southern Kherson region, liberating towns and villages...’}]
Output

Hugging Face
You can try it out yourself at Hugging Face. Many models are accessible to use, such as the ones explained above. Search for facebook/bart-large-cnn and dslim/bert-base-NER to start experimenting with your text.