How we detect involuntary calls to the 112
The Belgian emergency call centres 112 for ambulance and fire departments handle about 2.660.000 incoming calls each year. Out of these 2,7 million calls, only 42-47% are real urgent emergencies. Other calls are non-urgent information (14%) or assistance (6%) requests, e.g. people asking for the most nearby pharmacist or a taxi, or people asking for a non-urgent intervention from the fire department like wasp nest removals or for a flooded basement during heavy rainfall. Next to this, up to 29% of the incoming calls are involuntary or accidental calls. This is mainly because 112 is the only number most smartphones can dial without unlocking the phone, the so-called pocket calls.
During peak moments like storm days with lots of structural damage, these involuntary calls add up with a larger amount of unnecessary (non-urgent) calls and may lead to queuing of real emergency calls and unacceptable waiting times for people with urgent needs, resulting in possible loss of lives or additional health damage. Emergency centres 112 strive to answer every call within five seconds, which is hard to achieve during such peak moments, especially if caused by unexpected force-of-nature events.
Therefore, the Belgian Federal Public Service Home Affairs, Directorate-General Civil Security, 112 emergency centres, teamed up with the innovation lab of the Federal Public Service Policy and Support, in order to conduct an experiment in this challenge. At ML2Grow, we are very proud to support this experiment with a proof-of-concept implementation called Hazira Digital.
Call classification
Throughout the implementation, three types of calls were considered: urgent, non-urgent and involuntary.
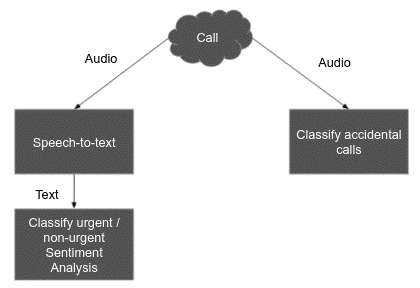
As most people in the AI world would suggest, an interactive system based on speech-to-text and natural language processing (NLP) seems appropriate for this challenge when properly trained and used with a good dialogue script. As such we believe a speech-to-text solution provides the necessary building block for this solution to facilitate text classification. Integrated into a VoIP server, Hazira Digital could take the incoming calls, greet the caller and ask for their emergency, handing real emergencies over to a human operator. This is in four languages but with a focus on Dutch and French.
However, next to budget limitations, there are some other constraints as we are dealing with highly sensitive personal data:
- Personal data (being part of written call descriptions or the audio files or streams themselves) may not leave the physical location of the emergency centre 112
- The use of personal data for training purposes by ML2Grow staff should be as limited as possible
This implies model building and training in-house, on-premises at the emergency centre 112, with the first 30 seconds of a maximum of 300 recorded calls: 100 of each category. These calls were manually selected and labeled by employees of the emergency centre.
It is obvious that urgent calls falsely classified as involuntary or non-urgent should be avoided and highly penalized, as this might impose people in real danger of not getting through to a human operator. To fully eliminate the risk of lost emergency calls, in practice involuntary and non-urgent calls could be placed on a waiting list that can be escaped by pressing a key after notification, and one can opt to activate the system only when queuing occurs. Hazira Digital is not a system to replace human operators but to assist them and prioritize the calls with the (probably) greatest impact when queuing might occur.
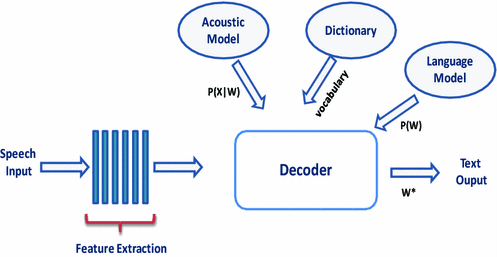
The NLP approach: popular speech-to-text engines reviewed
Due to the privacy limitations, any use of powerful speech-to-text APIs commonly encountered in cloud systems is excluded a priori. We, therefore, evaluated three open-source speech-to-text engines to provide input for an NLP call classifier: CMUSphinx, Mozille Deepspeech and Kaldi. All three are open-source libraries extensively used on on-board (offline) systems by a broad community, all with their own scientific approach, but with the same base as illustrated below.
Conclusion on speech-to-text engines and NLP
All three libraries feature quite good performance for the English language, but for Dutch and even French, we evaluated their performance on the data for this project as insufficient. Results were too unstable in order to be used reliably for text classification. This is mostly due to the lack of enough proper (labeled) training data with Belgian Dutch and Belgian French, which is quite different from Dutch Dutch. Also not enough Flemish or Belgian French dialects are included in public training data. Next to this, the audio files from the emergency centres 112 have 8 kHz audio quality whilst the above-discussed models require 16 kHz audio quality so the models automatically perform badly.
As for retraining a speech-to-text solution from scratch and gathering training data was well beyond the scope of this project, no major steps were taken to improve this performance. Specifically trained commercial language models like Phonexia (used by the Belgian company MyForce in their commercial platform) could be evaluated next as they allow on-premises implementation. Also, the IBM Watson STT libraries can be used on-premises with cloud satellite technology and might provide better performance.
Within the constraints of the experiment, NLP all of a sudden seemed no longer an option to classify incoming calls in urgent and non-urgent calls.
Audio classification of invalid calls
As involuntary calls still make up to 29% of the incoming calls, another approach was evaluated in order to detect and eliminate these calls. This still enables the 112 centres to prioritize actual voluntary calls during peak moments, allowing faster and more efficient support in real emergencies, thus saving lives and preventing health damage due to delayed interventions.
In order to distinguish voluntary from involuntary calls, we skipped the speech-to-text step and focused directly on audio classification. With the proper architecture and massive amounts of data, such a classifier would actually start to recognize words but right now the hypothesis tested was that involuntary calls will clearly have a different spectrum.
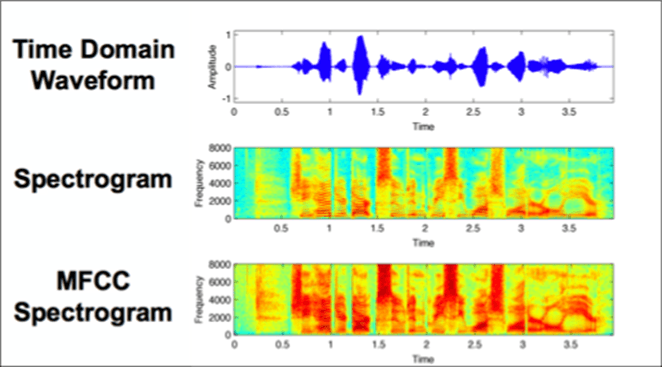
In order to achieve this, we transformed the audio file into a spectrogram (both normal and MFCC spectrograms). These spectrograms indicate the intensity (by means of colour) over time for a wide range of frequencies.
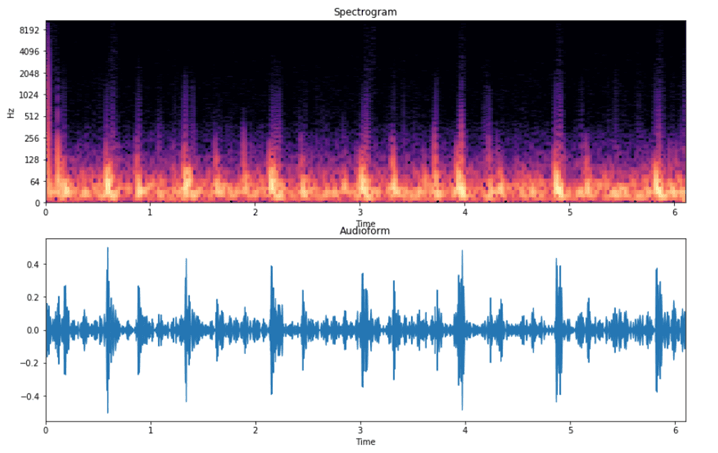
This way, the spectrogram can be treated as an image rather than an audio file, which enables the use of powerful image-based techniques in machine learning. This allows us to find patterns in the spectrogram and extract the unique DNA of the call represented by a set of numbers. These numbers will be the features used by a call classification Machine Learning (ML) model that can be trained with (invalid, urgent and non-urgent) calls in order to find correlations in the DNA of the calls in each category. Our final model returns the probability of the call belonging to a certain class assisting with decision making, as illustrated for a sample call below:
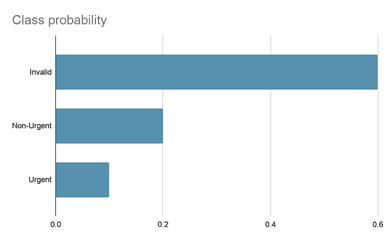
As we want to avoid urgent calls being identified as invalid, which has a higher risk on human lives than the opposite, we could only label a call as invalid when the identified probability of being an invalid call is high enough.
We applied a couple of tricks based on prior knowledge and data properties to help us with the fact that we only had a small set of data available. After a first round, we detected some interpretation issues which had happened during data labeling: e.g. when a road accident happened, the first call was labeled “urgent” whilst a second call from another caller about the same accident was labelled by the operators as “non-urgent” because no more action was needed. This knowledge of prior calls could not be detected by the ML model, so labeling was adapted in order to have the same notion about the classifications.
Even in this experimental setup with a training dataset of only 300 audio fragments of 30 seconds from real (voluntary and involuntary) calls to the emergency central 112, we already reached a precision of 84% in identifying involuntary calls.

| Precision | Recall | |
| INV vs U+NU | 84% | 67% |
| U vs NU | 58% | 87% |
One might expect a higher precision in distinguishing between urgent and non-urgent calls as people in danger use another intonation or a more stressed voice than people asking rather informational questions. This is however not always the case, as 112 is also quite often dialled by medical professionals (e.g. doctors offices) for real emergencies whilst they are generally calmer with an easier voice and intonation than people being in danger themselves.
In order to make this solution a real added value, especially to eliminate involuntary calls, the precision should be increased. This can be done using more data, and better data. The used audio samples for example include the voice of the call centre operator asking the caller what the emergency is, whilst there is no answer. In a real-world implementation, the computer will answer the call, so there can be focused on the sound coming from the caller rather than mixing up with the sound of the operator. The system is also focused on this precision in order to identify a call only as involuntary when the model has a certain level of certainty so the risk of voluntary and possible real emergency calls being identified as involuntary is minimized.
General conclusion
We were able to build a system that identifies involuntary calls with acceptable precision and identified opportunities to increase this precision in order to eliminate these calls and let the operators prioritize real emergencies, especially during peak moments, in order to save more human lives and prevent health damage due to delayed interventions.
To fully eliminate the risk of lost emergency calls, involuntary calls can be placed on a waiting list that can be escaped by pressing a key after notification. The system should only be activated when queuing occurs.
We implemented an open-source VoIP SIP server taking actual calls from test persons to demonstrate the functionality and readiness of this approach in order to be integrated into the operational environment of the emergency centres.
To further distinguish between urgent emergency calls and more informational calls, an interactive system based on speech-to-text and natural language processing (NLP) has to be trained and set up.
Thanks
This experiment was fruitful cooperation with the Nido Innovation Lab of the FPS BOSA and the direction and the technical team of the Liège emergency centre. We would like to thank all contributors to this result, which we know was quite an effort these times given the impact of covid19 on the emergency centre.
The system Hazira Digital is named after Hazira, one of the many operators from the Antwerp emergency centre 112 who got well known due to her performance in the Flemish broadcasters’ VRT reality series “De Noodcentrale” in 2016 where she used her angels’ patience and professionality to recognize a patient with breathing problems. It is our way to honour the many operators of the emergency centres 112 who save many lives on a daily basis.
