Understanding ChatGPT: language generation model
ChatGPT, developed by OpenAI, is an AI chatbot built on top of large language models and recently gathered widespread attention. Some specialists believe that we are on the brink of a revolutionary change, much like the impact of the internet in the 90s on the digital world as we know it today. Other experts remain sceptical and point out the limitations of current AI models.
In this blog post, we will go into the details of ChatGPT and explain in a neutral style which technology is under the hood.
What are large language models?
Large language models are machine learning algorithms which seemingly can analyse and understand text. They are deep neural networks that produce output which resembles human writing and can perform a wide range of natural language processing tasks, such as language translation, text summarisation, and sentiment analysis.
These models are trained on massive amounts of text data, such as books, news articles or even ‘the internet’, to learn patterns and relationships between words and phrases. The deep learning architecture allows these models to introduce a very high level of abstraction in language representation and processing, resulting in a behaviour appearing to the outside world as intelligent. The quality of the output generated by these models heavily depends on the amount and quality of the training data and the model’s architecture. Larger models typically perform better than earlier smaller variants. Although there are also plenty of benchmarks which indicate much smaller networks can keep up with their larger companions.
ChatGPT uses a specific variant of a ‘transformer architecture’ (more on that later) known as the Generative Pre-trained Transformer (GPT). After pre-training, the GPT model can be fine-tuned on smaller, domain-specific datasets to achieve even better performance at a specific task.
The transformer architecture
The transformer architecture is a neural network architecture for processing sequential data (such as text or speech) that has become a cornerstone of many state-of-the-art models in natural language processing (NLP). It was introduced in the 2017 paper “Attention Is All You Need” by Vaswani et al.
One of the critical innovations of transformer architecture is its use of self-attention mechanisms, which allow the model to weigh the importance of each word in a sequence when making predictions in a parallel framework. In contrast, traditional RNN (Recurrent neural network)-based models are/were notoriously slower to train as each word or input has to be processed sequentially.
Transformers are also far superior to RNNs on longer sequences, which was the key innovation factor for its development with the seq-to-seq model for Google. The issue with LSTMs (long short-term memory) was an ‘information bottleneck’, drastically decreasing the prediction quality when the model generated longer sequences. This is a critical issue to solve for real-world applications; look at the extremely long result prompts from ChatGPT now.
As the transformer architecture is highly parallelisable, it can make full use of GPUs or TPUs, and this makes it possible to train larger models with millions of parameters. This has helped drive many recent advances in NLP, as models with larger capacities can learn from more data and perform better on a wide range of NLP tasks.
Several training objectives are commonly used to train large language models. Two of the more popular methods/concepts are “next-token prediction” and “masked language modeling”.
In next-token prediction, the model is trained to predict the next word or token in a sequence of text. For example, given the input text “The cat sat on the”, the model would be trained to predict the next word rug”. This approach is often used in models like GPT-2 and GPT-3, based on a transformer architecture that can process long text sequences.
Masked language modeling, on the other hand, involves randomly masking (i.e., hiding) certain words or tokens in the input text and then training the model to predict the missing words. This approach is used in models like BERT, designed to capture bidirectional relationships between words in a text sequence.
During training, the model is presented with a sentence or paragraph where some words have been replaced with special mask tokens. The model is then tasked with predicting the original words based on the surrounding context. This approach encourages the model to develop a deeper understanding of the relationships between words and phrases in a text sequence.
In addition to these techniques, there are many other methods and concepts which are used for large language models, including pre-processing using unsupervised learning, reinforcement learning, and transfer learning. Overall, the training process for large language models is complex and time-consuming, requiring large amounts of high-quality data, powerful computing resources, and careful fine-tuning of model hyperparameters. The most powerful models can only be constructed from scratch by large organisations due to their computational and data needs.
![]()
What makes ChatGPT different?
ChatGPT is ‘simply’ an artificial intelligence chatbot built on top of a large language model (GPT-3 or GPT 3.5, to be more exact). Starting from this wealth of knowledge, ChatGPT was specifically fine-tuned to be able to have meaningful conversations with humans. This was mainly the result of a lot of effort made by human trainers using both supervised learning techniques, as well as reinforcement learning to allow for this more humanlike interaction.
In the training process, the human AI trainers played both sides (the user and the AI assistant) in conversations. Furthermore, human trainers ranked the quality of replies to be used in a reinforcement learning framework. Doing so eventually led to the chatbot being able to interact in a conversational way with specific ‘humanlike features’ that have not been seen before, or at least not with such accuracy. The most remarkable features of ChatGPT include the ability to interact using follow-up questions and responses and the ability to understand and use specific instructions to tweak replies. As we have all seen, this allows ChatGPT to create programming code, songs, poems or other creative content instead of just being a knowledge source. In addition, ChatGPT is able to question the validity of certain premises put forth by the user and can accurately link information from previous input and replies to downstream questions.
The training mechanisms that have led to these amazing features have also raised some challenges, as the RLHGF technique (Reinforcement Learning from Human Preferences) can (further) ‘reinforce’ human bias in the model.
Most criticism of ChatGPT by experts originates from the fact that inherently it is still just a ‘very sophisticated next-token predictor’ as can be seen by the way it generates replies. Simply put, critics like to point out that the system does not reason but is just very good at guessing which words make sense as a reply. This inherent ‘flaw’ can be seen in specific shortcomings such as ‘hallucinations’ where ChatGPT generates seemingly plausible information and confidently presents this as a truth, although there is no objective basis for it. Some experts have also stated that a true AI should be a system that provides reproducible output. This is not the case for ChatGPT, as small variations in the way the question is put forth can lead to replies that differ in a meaningful way. These flaws are also dangerous, as ChatGPT will inevitably introduce fake news and information back to knowledge bases by accident and deliberately.
Let us not forget that discussions about whether a piece of technology is really ‘intelligent’ are important, but as interesting is the question if this piece of technology can create business value. Despite the limitations, many people have been blown away by how powerful ChatGPT is, even surprising experts in the field. It is beyond doubt that ChatGPT can create business value if used with the proper disclaimer.
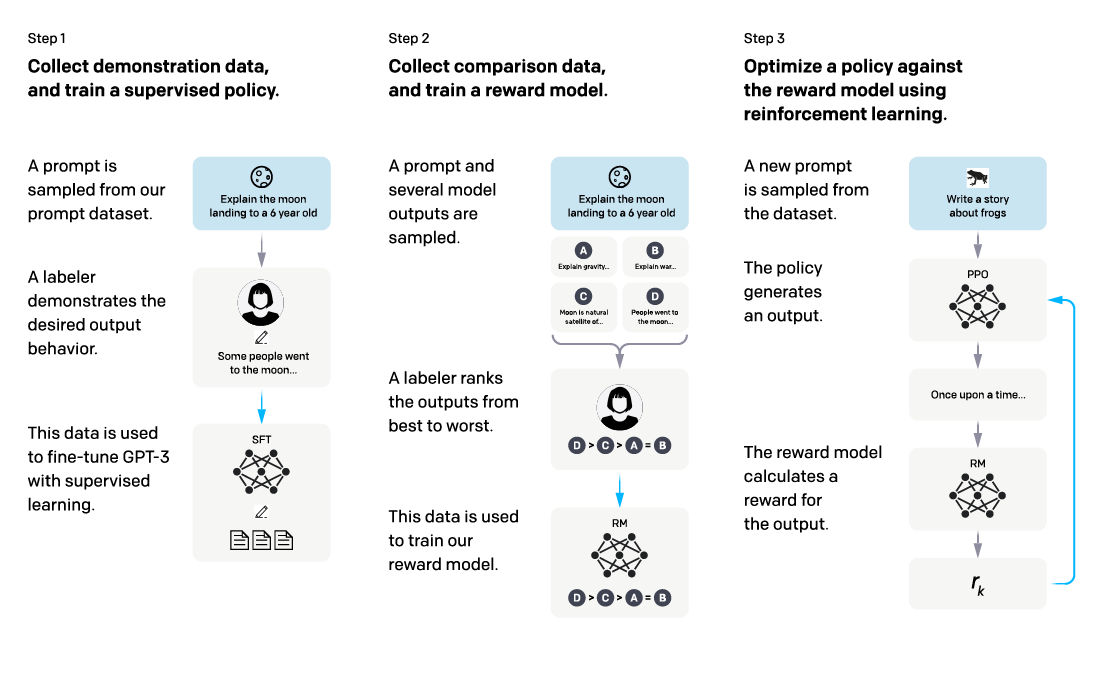
Source: training language models to follow instructions with human feedback OpenAI et al., 2022 https://arxiv.org/pdf/2203.02155.pdf.
Expert already knew and understood the power of AI systems for specific tasks. However, it is the fact that ChatGPT excels at the specific task of having a conversation, a concept so fundamental to human society, that made it so that the world including the experts were stunned by its capabilities.

ML2Grow & ChatGPT
Did ChatGPT spark your curiosity about what AI can do? You are not the only one.
It is likely that AI technology is part of the solution you are looking for. However, you should know that ChatGPT is only a very small example of a much larger pool of AI solutions that are available nowadays.
AI is like electricity, as coined by Andrew Ng. We fully embrace this at ML2Grow; AI will be omnipresent, empowering solutions in the background. Investing in AI will help your company or organisation to stay ahead of the curve and remain competitive.