Synthetic data: a game-changer for AI

What is today’s most valuable resource? Is the answer oil, gold, perhaps natural gas? According to the Economist, five of the most valuable companies in the world would argue that the answer is data.
Data is indeed the most valuable asset of some of the biggest companies in the world and it is also the fuel that powers artificial intelligence applications. The most challenging part of building a powerful AI is getting the right data. Collecting quality data from the real world can be complicated, expensive and time-consuming. In addition, in some use-cases, the data should cannot and should not be collected at all because of ethical or privacy concerns.
Therefore, alternative ways to gain data can be the key to success to build AI solutions.
Recently, the option of creating synthetic data has gained more interest by the community as it can often be generated en masse, while respecting the privacy of people.
Let’s have a a closer look at what is happening.
The rise of synthetic data
The concept of synthetic data is not new, but it is now reaching maturity when it comes to generating real-world impact. It’s a simple concept: instead of gathering ‘real’ data, efforts are spent to generate realistic synthetic data. If this is possible, it often enables practitioners to generate as much data as they need, on-demand and tailored to their precise specifications.
According to a Gartner study, 60% of all data used in the development of AI will be synthetic rather than real by 2024. That’s a bold prediction and it this becomes reality one day, it would definitely change AI development.
Autonomous driving
While synthetic data has been around for decades, the concept gained more attention in research revolving around creating autonomous vehicles.
Unsurprisingly, Tesla was one of the first to grasp the potential of synthetic data and AI. Indeed, Tesla has arguably attracted more machine learning talent and relatively invested more in AI than its competitors.
Synthetic data and autonomous driving go hand in hand. Collecting real-world data for every conceivable scenario a self-driving vehicle might encounter on the road is impossible. Given the unpredictable and unbounded world, containing all the necessary data to build a genuinely safe autonomous vehicle would be impossible.
Instead, car companies developed sophisticated simulation engines to generate the requisite volume of data synthetically and efficiently expose their AI systems to millions of driving scenarios. For example, they can dynamically alter the locations of cars, adjust the flow of pedestrians, increase or decrease vehicle speeds, change the weather and so on.
But it didn’t take long for the AI community to recognize that the synthetic data capabilities developed for car companies could be generalized and applied to other machine learning applications.
For example, other computer vision applications, ranging from robotics to monitoring and geospatial imagery to manufacturing often require high volumes of (labelled) data.
How to create synthetic data with AI models?
Curiously, AI models can also be used to generate synthetic data to feed other AI applications.
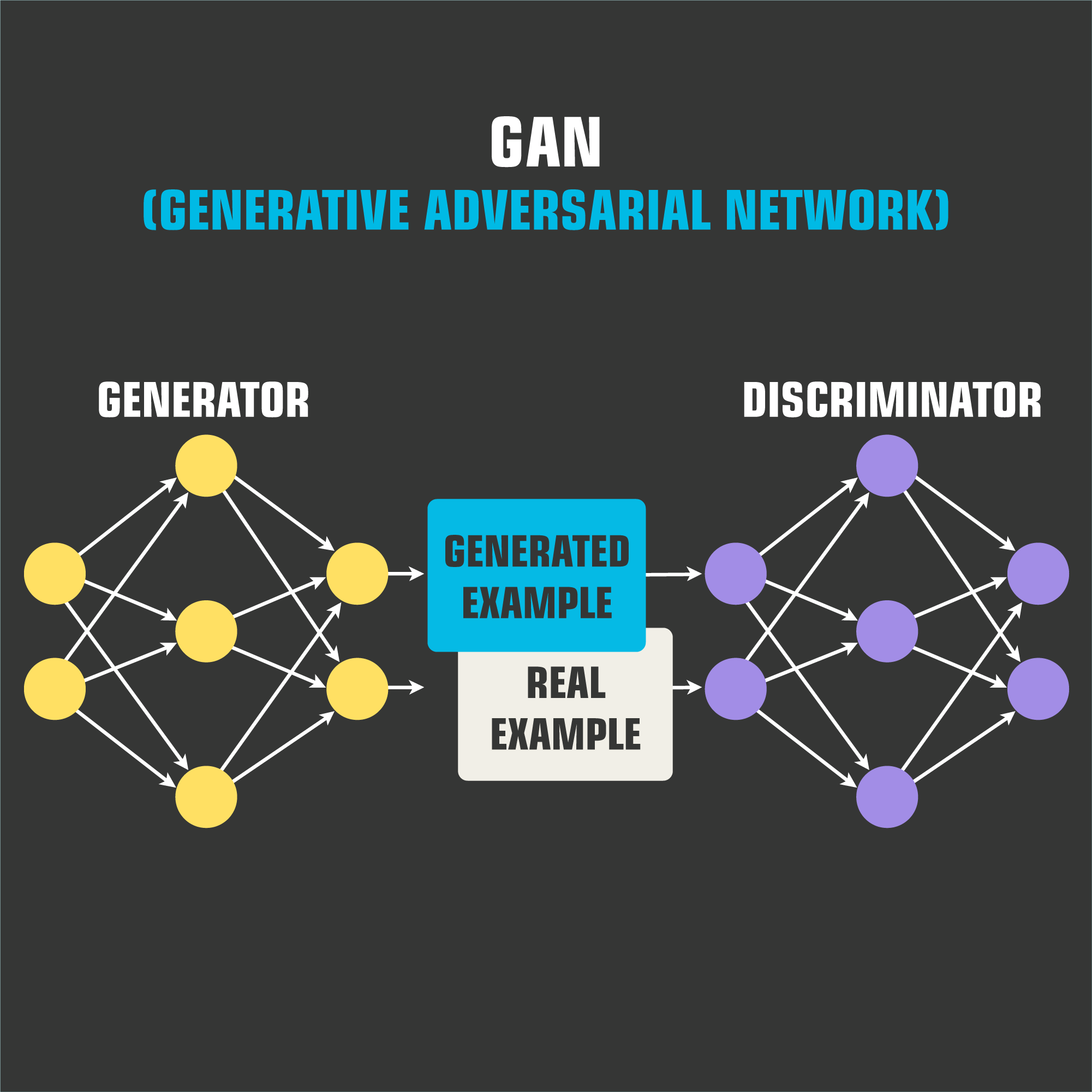
For example, Generative Adversarial Networks or GAN’s are able to generate high-fidelity,realistic image data.
In our previous blogposts, ‘getting creative with generative adversarial networks, ‘finding your face in a machine learning model,’ and ‘transforming your face with Machine Learning‘, we explored the concept of GANs and how these AI models work.
In a nutshell, GAN were proposed by AI pioneer Ian Goodfellow around 2014. The premise is to pit two separate neural networks. The first component (the “Generator”) tries to mimic this data, while the second component (the “Discriminator”) tries to distinguish between this output and the real data.
The generator is trained to create better images until the discriminator can no longer see the difference between the generated and original data. This setup is a zero-sum non-cooperative game or minimax. Typically the learning process reaches the famous Nash equilibrium from game theory.
Two other essential research advances driving recent momentum in synthetic visual data are diffusion models and neural radiance fields (NeRF).
Diffusion models are also generative, meaning they are used to generate data similar to the data on which they are trained.
Diffusion models are now the talk of the town in the AI community. It is the technological backbone of DALL-E 2, OpenAI’s much-anticipated new text-to-image model. With some meaningful advantages over GANs, expect to see diffusion models play an increasingly prominent role in the world of generative AI moving forward.
NeRF is a powerful new method to quickly and accurately turn two-dimensional images into complex three-dimensional scenes, which can then be manipulated and navigated to produce diverse, high-fidelity synthetic data.
One language to rule them all
While synthetic data will be a game-changer for computer vision, the technology will unleash more transformation and opportunity in another area: natural language processing
Language defines us as humans. The ability to cooperate and communicate has been one of the most critical drivers to becoming the dominant species on the planet. It is also at the core of every vital business activity. This is reflected in the vast potential for text-based synthetic data.
Natural language processing enables computers to understand human language. Computers can naturally process this data much faster than humans, so companies are now turning previously unused data into meaningful information. For instance, information can be automatically extracted from internal reports, service logs or case files and interpreted by computers. You can read more about it in our blogpost about NLP.
An example to demonstrate the potential of synthetic data in a language is Anthem. An American health insurance company and one of the biggest in the world. They are now working with Google Alphabet to create a synthetic data platform that will let Anthem better detect fraud and offer personalized care to its members.
Among other benefits, synthetic data addresses the data privacy concerns that have held back the deployment of AI in healthcare. Training AI models on real patient data present many privacy issues, but those issues can be avoided when the data is synthetic.
It is important to note that most companies still use classical statistical methods or traditional machine learning to generate synthetic data, focusing on structured text. But over the past few years, the world of NLP has been revolutionized by the introduction of GPT-2 and GPT-3.
Open AIs GTP-3 is able to produce a massive amount of text with a level of previously unimaginable realism, originality, sophistication and diversity.

OpenAI has shared some fascinating insights about GPT-3, which generated an article that is the hardest to date to distinguish from a human-written text. Only 12% of respondents thought that the article was machine-generated.
However, we still be careful to not only see the positive aspects of synthetic data.
The higher the fidelity of synthetic data, the higher the risk that it will be increasingly similar to real-world data, which someone can reconstruct. This problem will be if real-world data is sensitive, such as medical records or financial transactions.
So where is this going?
Well, we don’t really know. But according to the graph below, made by Gartner, synthetic data will completely overshadow real data in AI models by 2030.
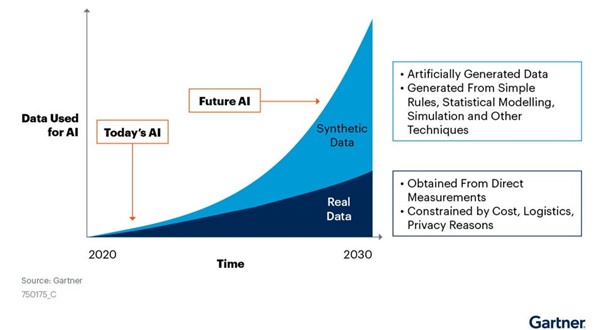
Source: Gartner
As synthetic data becomes increasingly adopted in the years ahead, it has all the traits to make a significant disruption across all industries. It will transform the economics of data.
By making quality training data vastly more accessible and affordable, synthetic data will undercut the strength of proprietary data assets as a durable competitive advantage.
In the past decade, the mantra for every investor in tech was: who has the data? One of the main reasons that tech giants like Google, Facebook and Amazon have achieved such market dominance in recent years is their unrivaled volumes of customer data.
Synthetic data has the potential to disrupt this. By democratizing access to data at scale, it will help level the playing field, enabling smaller companies to compete with more established players that they otherwise might have had no chance of challenging.